Dashcam Explorations
Some updates on some of the things I've tried to extract out of the hours of dashcam footage I've attained.

A personal love that I have toward algorithms is the various forms of analysis one can do using them. Oftentimes, military- and industrial-grade algorithms are made public in the name of innovation (aka open source code!). These algorithms typically are fine-tuned for specific situations: think identifying people in surveillance footage, grouping objects semantically, and image analysis like seams, edges, and pixel differences between frames.
In a previous post, I (poorly) explained how I used SAM2 and Canny Edge Detection to create long plots of my drives through the Midwest USA. The starting input I used prior was slitscans – made by taking a column of pixels from every nth frame and combining these columns into one image – from my dashcam footage, to take advantage of a plotters ability to draw large and long. I’ve moved my end product to a website, thus removing the need for a slitscan.
The two main explorations I did is as follows.
Segmentation

Facebook Research has sort of headlined the pursuit of accurate semantic segmentation, the newest update being SAM3. In each SAM[x] update (SAM standing for Segment Anything Model), you are able to hand the model an image or video and receive a collection of masks where all pixels in the mask corresponds to the same ‘object’. SAM3 brought an update of text input to segment video.


After the recent Pittsburgh snowstorm, we got a bunch of snow dumped on us. The above are attempts using SAM3 and the text prompt ‘snow’ to segment the video. As seen above, it wasn’t very successful in isolating just the snow out.
SAM3 is also able to assign negative and positive weights to pixel areas (like its predecessor SAM2). I made a small program to assign such weights to the first frame of the input footage and propagating the results out to the rest of the frames.
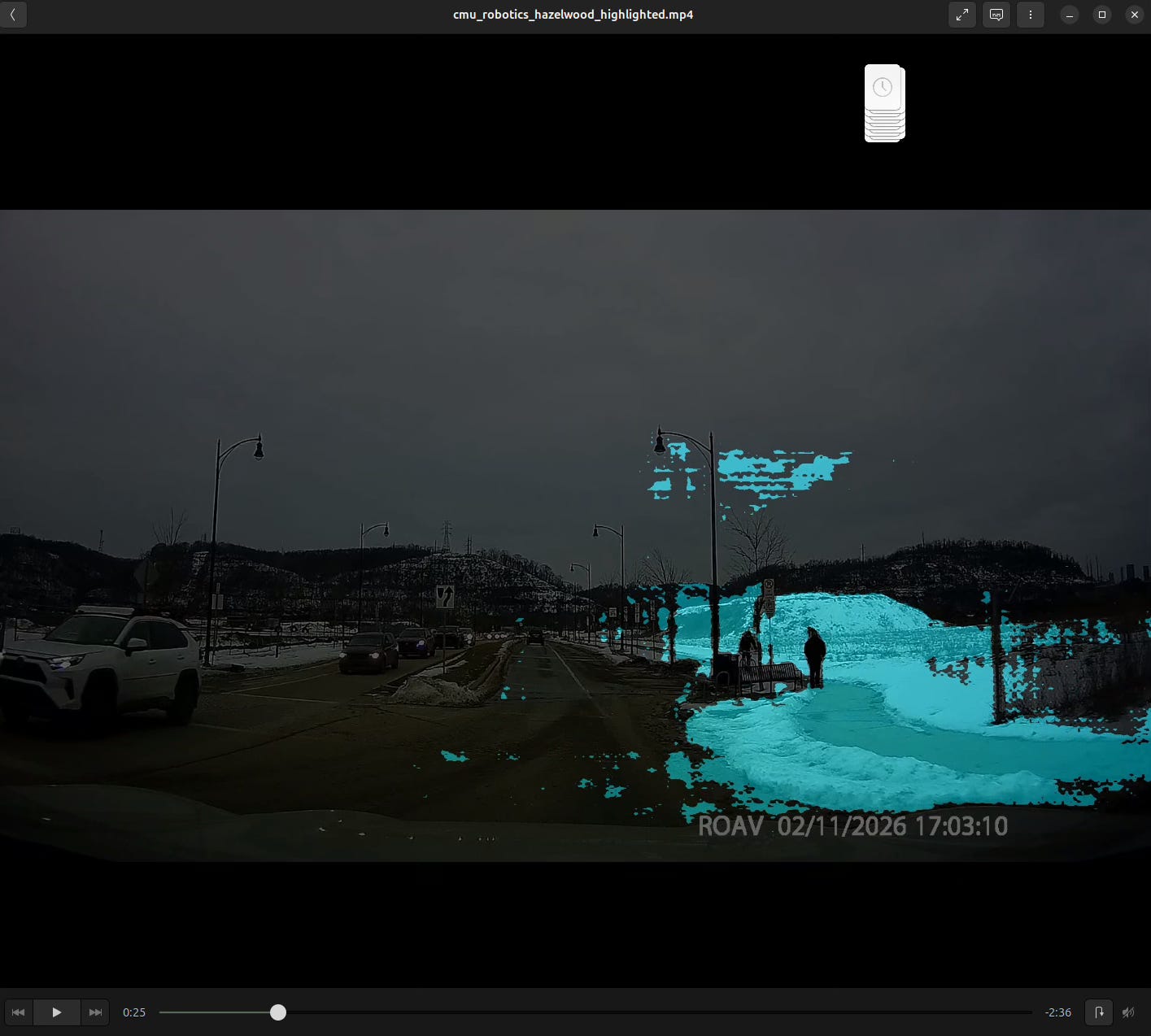
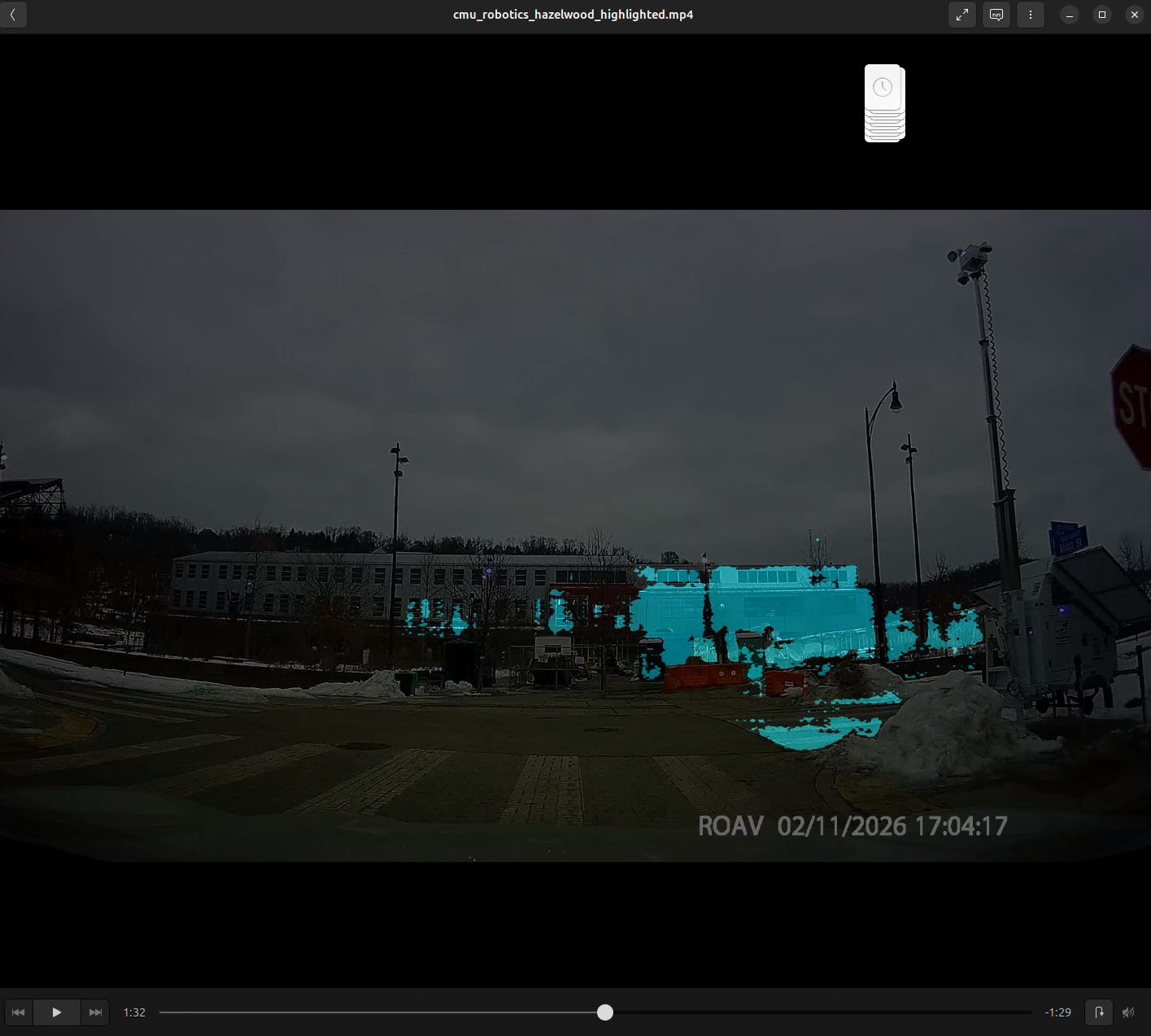
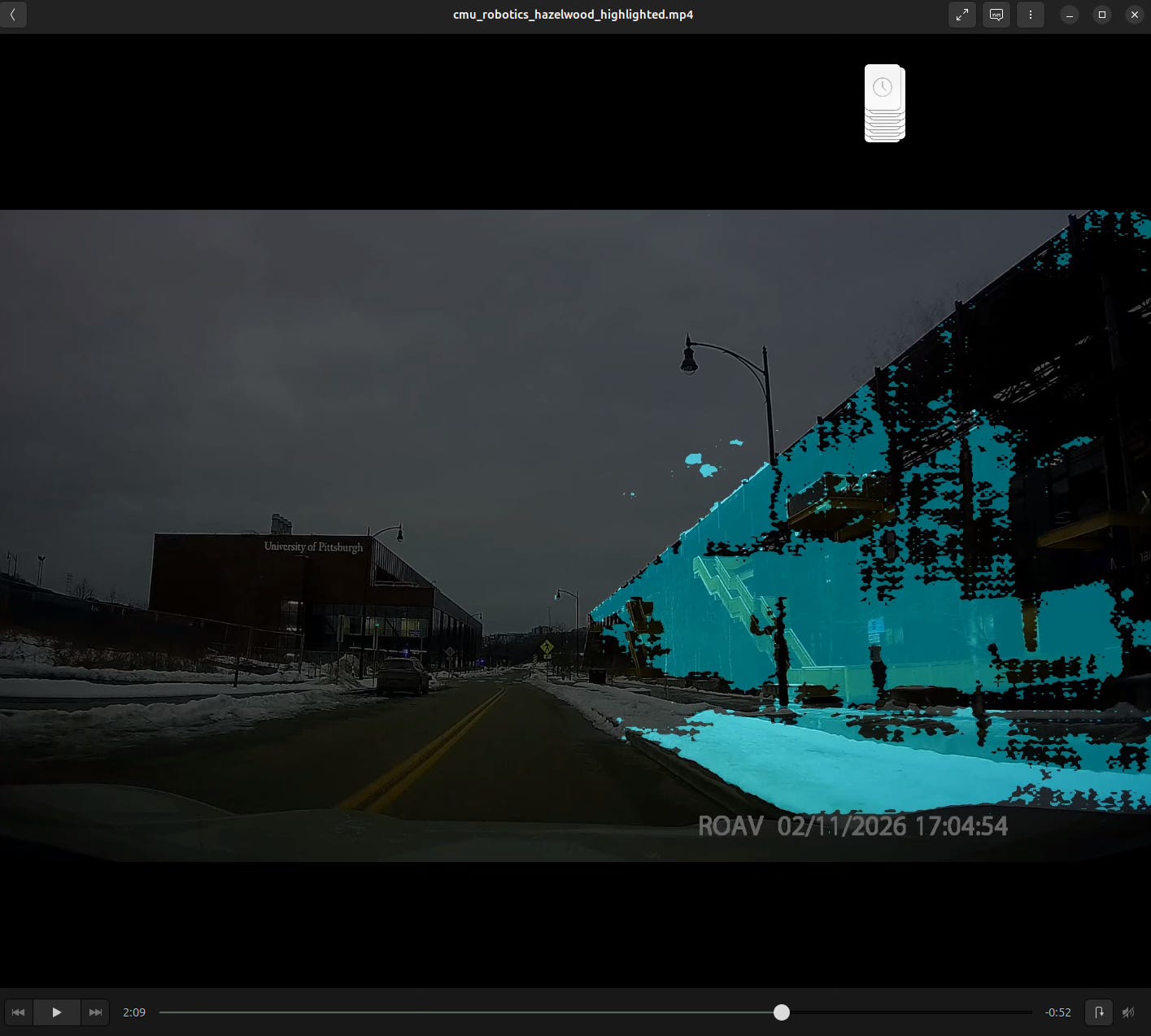
In certain footage (the first image above), the segmentation is actually somewhat successful. However, the success decreases as the weights are propagated out to later frames. This likely will resolve itself as more weights are assigned to later frames, i.e. weights are assigned >= 5 times in a sequence of frames.
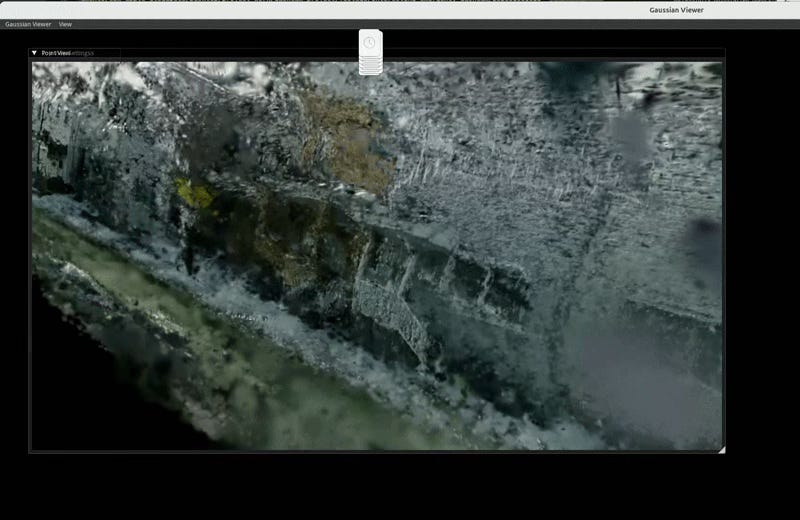
Splat Reconstruction
I got to see Inria’s new On the Fly Novel View Synthesis paper at SIGGRAPH 2025 and thought this technique might be somewhat applicable to dashcam footage. However, a few caveats. Inria’s paper (along with most reconstruction techniques) assume a pinhole camera model. Most dashcams, including mine, use a wide angle lens to capture more. Additionally, this method assumes that the camera is consistently in a forward motion, which isn’t necessarily always true when you’re driving (think parallel parking). However, with the power of OpenCV and a printed chessboard, we can correct our wide angle lens and give a closer-to-pinhole-camera-model footage to this On the Fly NVS model.
Results are as followed.




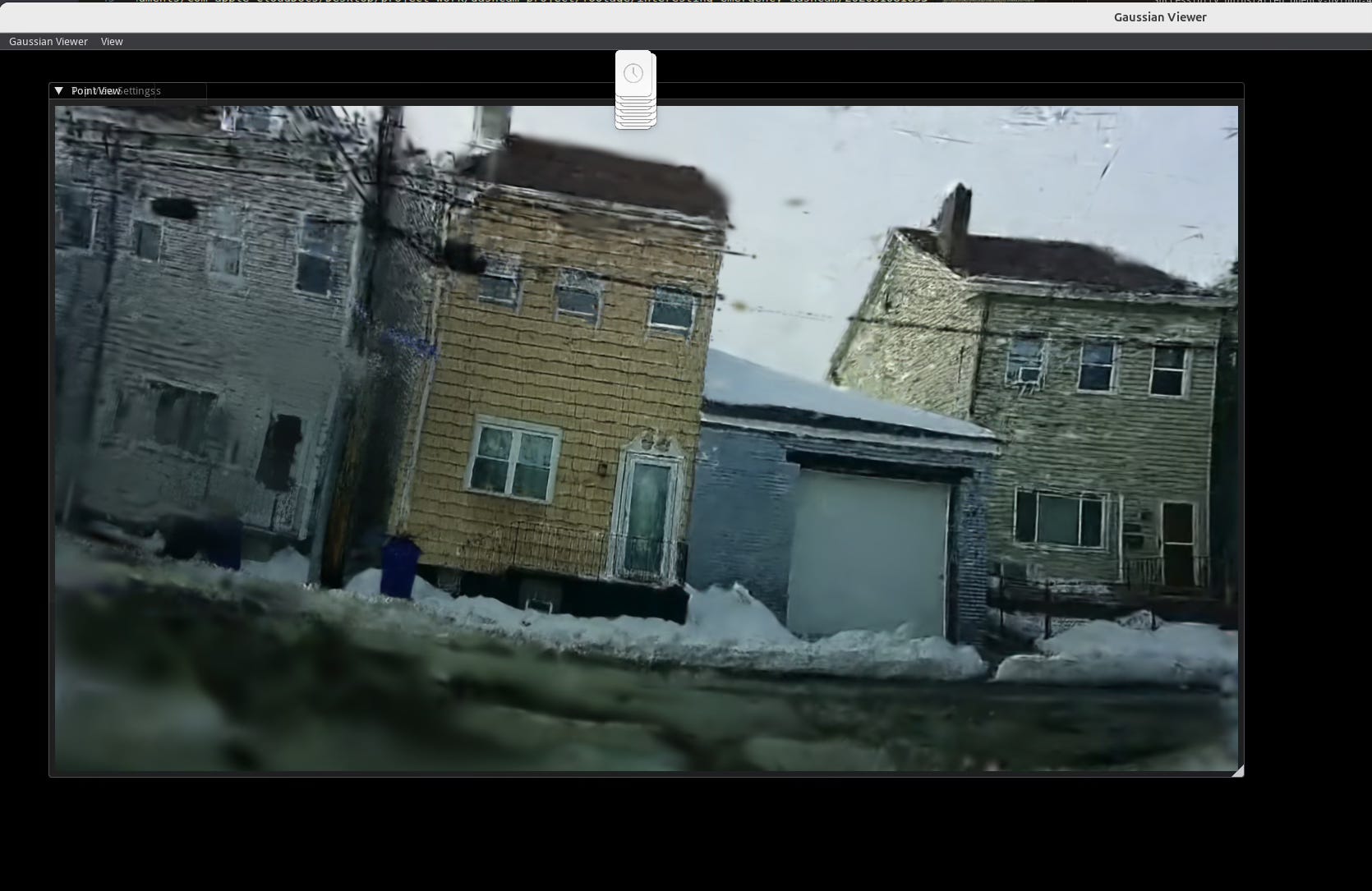
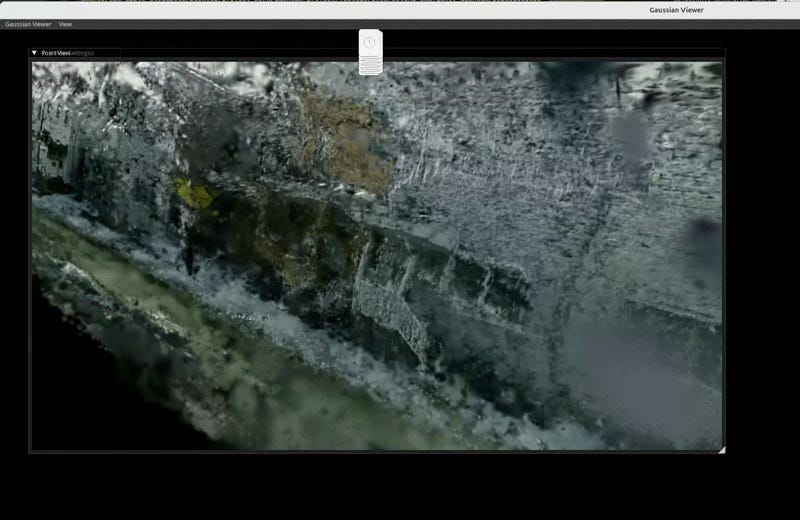
Musings
I’m still thinking on what exactly can result out of these analyses. One idea is to hope for some snow and then drive the greater Oakland, Schenley Park, and South Squirrel Hill area to make a navigable splat recreation using spark.js (I have a working local site to navigate a single splat).
My prof (@Golan Levin) proposed using SAM3 to see what the city of Pittsburgh looks like purely through the location of sneckdowns and/or the positioning of snow.

Unfortunately, I started most of this exploration after the snowstorm. If I could, I’d give someone in NYC a body cam to do something similar after their incoming blizzard. Or drive up north to somewhere with snow on the ground and a large pedestrian presence.
I do think it’s interesting to think about how people’s interactions define a space and vice versa. In parts of the resulting splat, there’s almost ghosts of human existence.

Questions
What do these explorations tell us about our environment? Who knows how use of these algorithms will contribute to the design of our environments.
OK, just yapped too much, bye!
– l.chen