Capstone/Final Undergraduate program Thoughts
A slightly edited stream of consciousness. (edit: not really edited at all)

My friend sent me an article a week ago that linked to Paul Graham’s (Y Combinator founder) 2003 article titled “Hackers and Painters” that I wished I had read pre-university. Growing up in the Midwest, I didn’t grow up surrounded by the same level of technological culture that many of my peers at CMU seem to have experienced. The parallels that run between the act of painting and coding are so clear to me that I saw no other path to take but to pursue both in university. But as all creative technologists/hackers/artist/researchers struggle with, how would this look?

I’m about to wrap up my BCSA degree at CMU and I thought it would be fun to look back on some of the most formative projects I’ve done that I’ll be continuing to push in my capstone, both as a form of summarizing what I’ve learned and what I shall take with me beyond my years at CMU. Through luck and happenstance, the following projects are what I think a multidisciplinary pursuit can result in.
dead things in jars
More detailed documentation here.
As apart of multiple projects in Professor Golan Levin’s Experimental Capture course, I was introduced to the popular 3D reconstruction technique of 3D Gaussian Splatting.
In layman’s terms, 3DGS is the process of training a model to represent a 3D scene through a set of gaussian primitives. These gaussian primitives are view-dependent (meaning the appearance rendered on a screen changes with the camera perspective). Think of them as 3D blobs where attributes like opacity, rgb color, etc are concentrated via a Gaussian Distribution from the center of the blob. Each gaussian primitive is centered at a point in a point cloud that is attained from traditional state-of-the-art SFM pipelines, like COLMAP, and later optimized according to some set of rules.
In dead things in jars, I made gaussian splats of a catalog of wet specimen. Wet specimen are biological specimens preserved in liquid – typically isopropyl alcohol after an initial preservation process involving formalin – for research and educational purposes. Through the generosity of the Carnegie Museum of Natural History and the Center for PostNatural History, I got to look at these specimen up close and personal.
Above is a reel of some of the splats trained using Polycam.
Rational for this application is as follows: 3DGS is very good at representing shiny, transparent, complicated scenes (like a dead thing in a jar!). Other 3D representations like meshes would fail to capture the entire medium of a wet specimen. I’m told by the folks working at the “Alcohol House” (colloquial term for CMoNH’s standalone building the houses all of their wet specimen for safety reasons like fire) that in past attempt of make 3D representations of the specimen in their collection involve taking the specimen out of its flammable container and using very expensive 3D scanners to make 3D models.
Humans use various mediums to preserve objects and the experience of holding the jar to view a winged lizard is very different from holding it in your hands. A 3D scanner may make a better mesh model for the lizard inside the wet specimen container but it fails to capture the delicate nature of specimen that entire format of a wet specimen alludes to. Additionally, some specimen can’t exactly be held. Take this example from the Center for PostNatural History:


That is a ribless mouse embryo. I’m not sure if you can hold it in a stationary position long enough to scan it. Additionally, wet specimen of flowers, which may involve translucency, will cause mesh reconstructions to hallucinate surfaces that don’t exist.
Confocal stereo on cameo gems at the Getty
I’m still in the process of writing proper documentation but the following will be a good first draft of it.


This project was supported by the various grants available to undergraduate students at CMU, the Getty Villa’s Digital Imaging Team, and wonderful guidance from Professor Golan Levin and Professor Ioannis Gkioulekas (whom I shall refer to as Yannis for the remainder of this doc) from CMU.
I had submitted a poor version of this for Professor Yannis’s Computational Photography course in the Fall of 2025, but the course served to be a much needed introduction to the implementation and use of various computer vision and graphics concepts, thoroughly familiarizing me with common toolkits in this field.
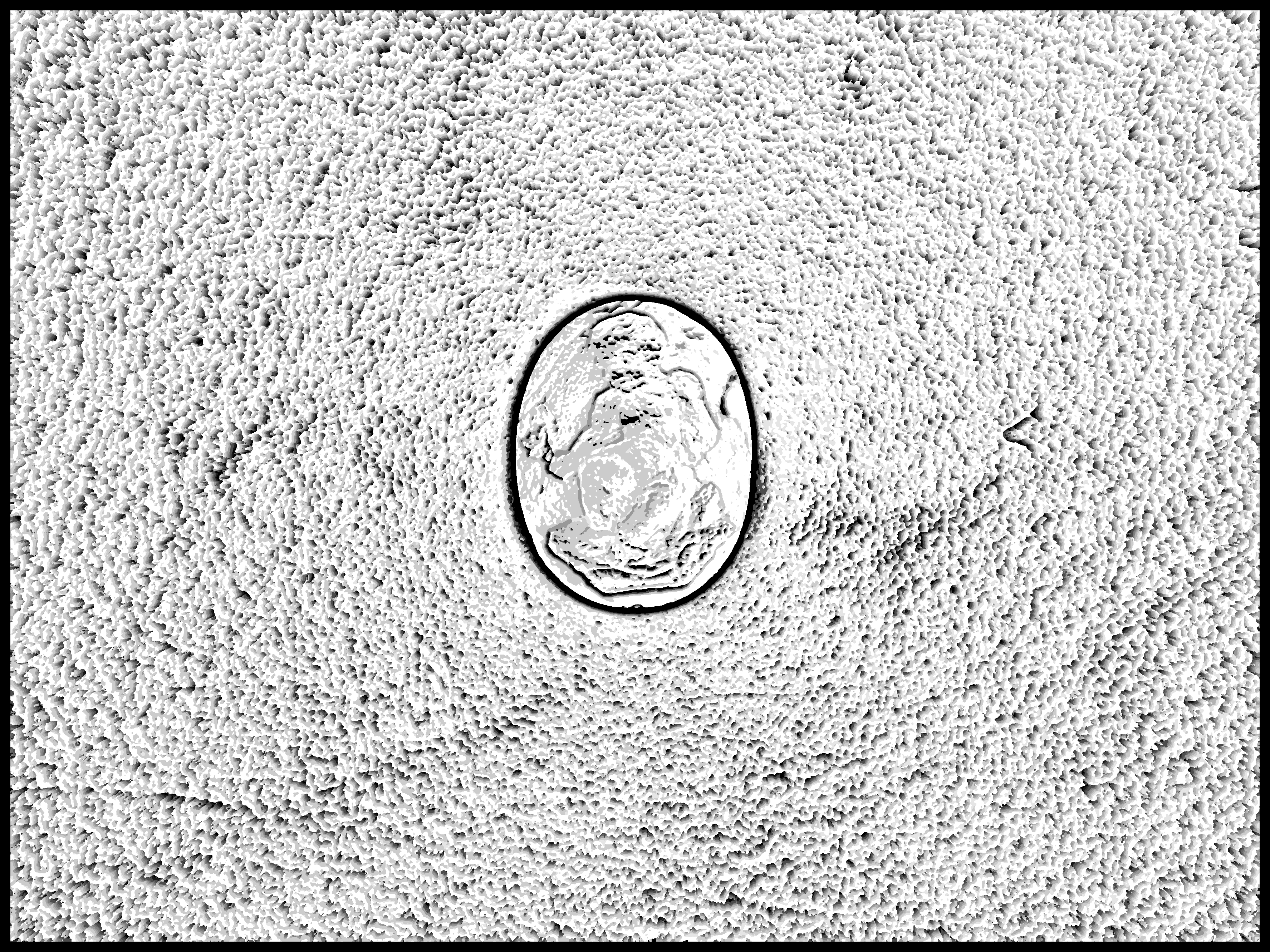
In December, I took a week after finals work at the Getty Villa taking many images of cameo gems. Cameo gems are gems produced using the cameo technique, wherein you carve a relief (raised, positive) image and use contrasting layered materials. It is my understanding that cameo artifacts are rare-ish and typically depict portraits of royalty or Greek/Roman mythological scenes. You typically find them in museums or, in my case, a private collection of some wealthy dead dude.
Confocal stereo is a method of computing 3D shape by strictly controlling the focus and aperture of the lens. If you know what focus-stacking is, this is that on steroids. If you don’t know what focus stacking is, it’s a digital imaging technique where you combine multiple images of a scene, each with a different focus depth, to create one super-duper focused image. It addresses focus issues in macrophotography and landscape photography. In cultural heritage, this technique is widely used to get high-fidelity images of everything from small gems to large sculptures. Niki Nakagawa, senior photographer at the Villa Imaging Studio, tells me that cultural heritage organizations like the Getty typically work with cameras and software optimized for focus-stacking. Industry standard includes Capture One software, Phase One cameras, and Hasselblad cameras to achieve high fidelity images.
Instead of introducing a need for new equipment, confocal stereo was chosen to take advantage of the software and hardware already present in cultural heritage institutions to get depth/3D shape data of various objects. However, the translucent nature of some gems (especially glass ones) resulted in quite noisy results (as depicted in the first image above). I would honestly love to attempt this technique again on a diffuse surface antiquity, like the following altars with relief decor in the Getty Collection:

Translucent and specular objects remains to be a challenge in the computational imaging field. The following are some more result and object image pairs of my work. In hindsight, I definitely should’ve cropped these lol.

This experience sort of solidified my insistence to explore ways of using analytical computational processes on culturally significant contexts. I have taken courses on using generative AI and what I’ve found is that strictly using generative AI tools (typically of the image/video generation kind, like MidJourney) is that the process isn’t involved enough to teach or expose something new to me. Cultural heritage is also a pretty fascinating field to me because it often deals with a lot of media theory nuances. “The medium is the message” is something I learned in a Decision Science course called Thinking in Person vs. Thinking Online and at least in the cultural heritage context, you’re often dealing with depictions of stories in mediums across time and a question that arises out of the pursuit of documentation is what one shall preserve in the newest technology. The History of Information is a lovely source that I encountered during my research of the history of cameo gems.
Ironically, it has proved to be the moments of major change in physical form—which one might expect to have increased the texts' chances of survival—that have seen the greatest volume of physical loss: the changes from roll to codex, from tribal scripts to Caroline minuscule, and from script to print; for once a body of literature is consigned to a new physical form, what remains in the old form, now redundant, is discarded" (R. Rouse," The Transmission of the Texts," Jenkyns [ed] The Legacy of Rome. A New Appraisal [1992] 42-43).
Truly, one of the questions I think we must think about more is what we are now capturing with the convenient tools born out of innovation. Selection and curation (and lack thereof) is baked into our understanding of life. Computational tools may allow us to hold a different record of what exists at a timestamp, allowing us to see how the passage of time affects the world around us in ways we can’t conceive at present. In more practical conservation contexts, 3D models of the Notre Dame aided in its reconstruction following the 2024 burning. In analytical contexts, part of my time at the Getty was spent touring the team at the Getty Museum and how other groups are working on conservation, dating pieces, and doing other 3D reconstruction tasks. There, a reflectance imaging spectroscopy camera worth probably a nice house in Pittsburgh (or a shed in LA) is used to identify pigments to date work. The tech behind it is a little lost on me but my understanding is that you have two cameras, one for visible light (rgb wavelength stuff) and a hyperspectral one that can capture light that isn’t visible, that get the reflectance spectrum for the materials of the object. From there, you can identify the material. Since certain pigments and materials only existed between specific periods of time, you can use the data from this camera to date a work to a very specific time period.
Anyways, this section is getting too long so let’s move on. I’ll write a reflection on this experience in another article with more pics and explanations for the math (to the best of my ability).
Dashcam Explorations
I wrote about it in two previous posts, with poor explanations and promising early ideas.
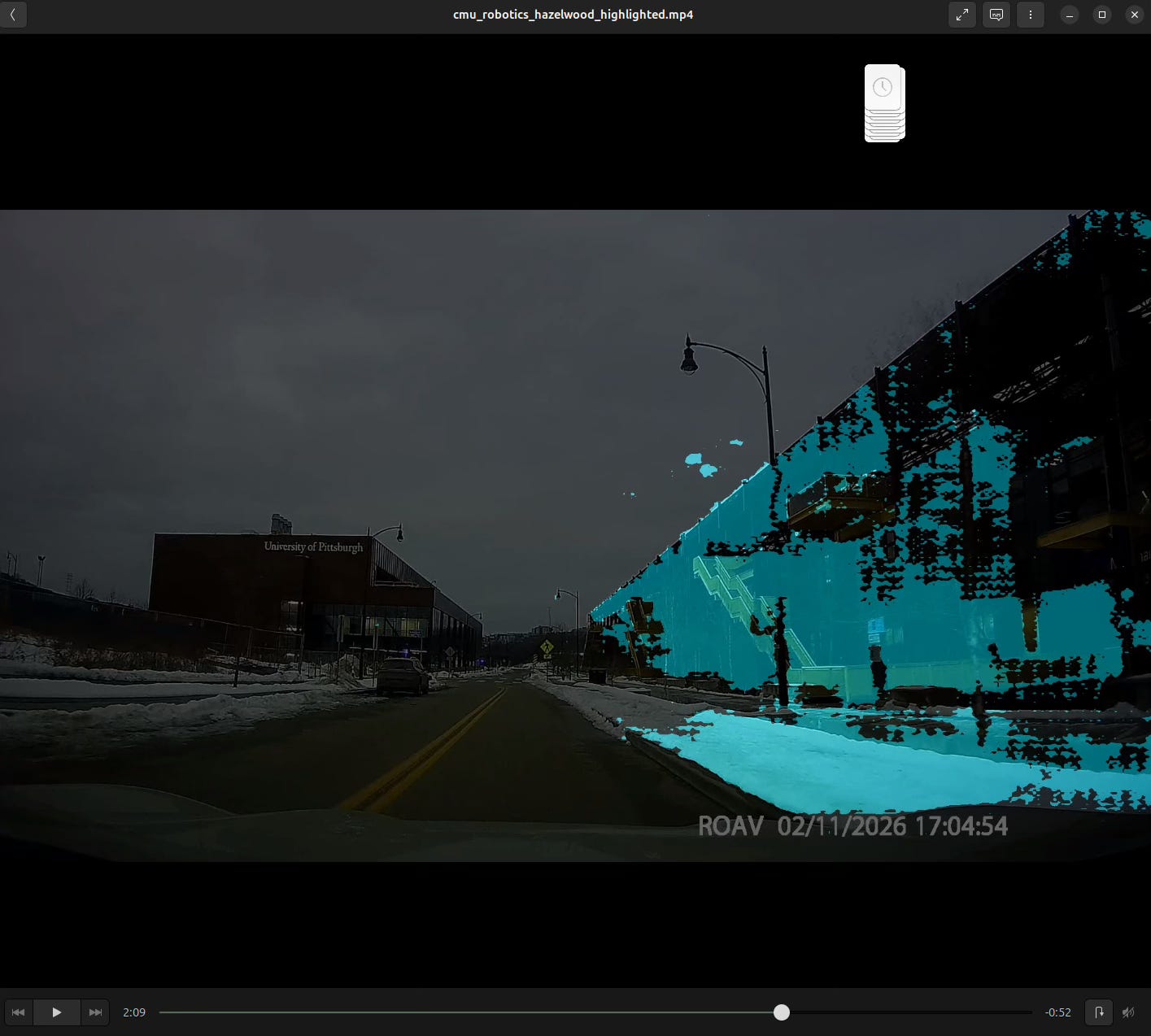
This was mainly a series of explorations of what I can make from dashcam footage. I finally got a car (thx mom) and I wanted to take advantage of that.
First, I hacked together a workflow to generate SVGs (scalable vector graphics) to plot. TLDR; process is as follows:
Process the footage using ffmpeg by extracting each frame from a 30-60 second video.

example footage 
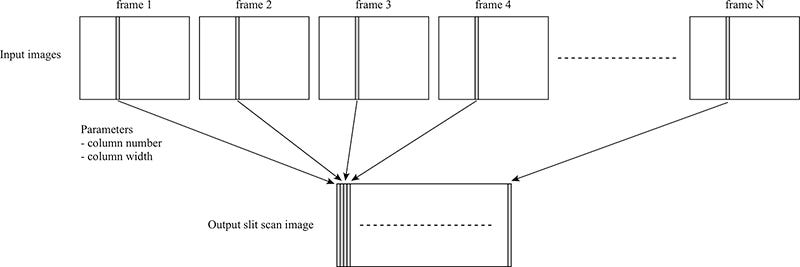
folder setup (don’t flame me for the naming system) Create a slitscan from said frames. Slitscanning is a technique that involves capturing a moving scene through a narrow slit over time. I did this in post by selecting a column from each frame and concatenating them all into one image. Paul Bourke (love him) has a good explanation and diagrams that I have displayed below, along with some of mine.
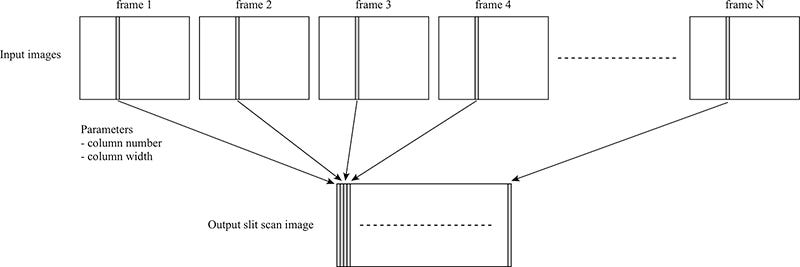
cred Paul Bourke 
slitscan from a drive from Pittsburgh back to home, where Apple Maps took me through the hills of Ohio for some reason) 
drive back at home on telegraph rd where my parents can be heard arguing about my driving in snowy conditions With these slitscans in hand, I segment them using SAM2 (Segment Anything Model 2, from Meta/Facebook Research). I saved each mask individually to use for the SVG generation part.

src slitscan can be seen above 
src slitscan can be seen above 
example mask 
another example With my slitscans and masks in hand, I used python and vsketch to generate the SVGs. Nothing interesting here, just did luminosity-based halftone hatching.
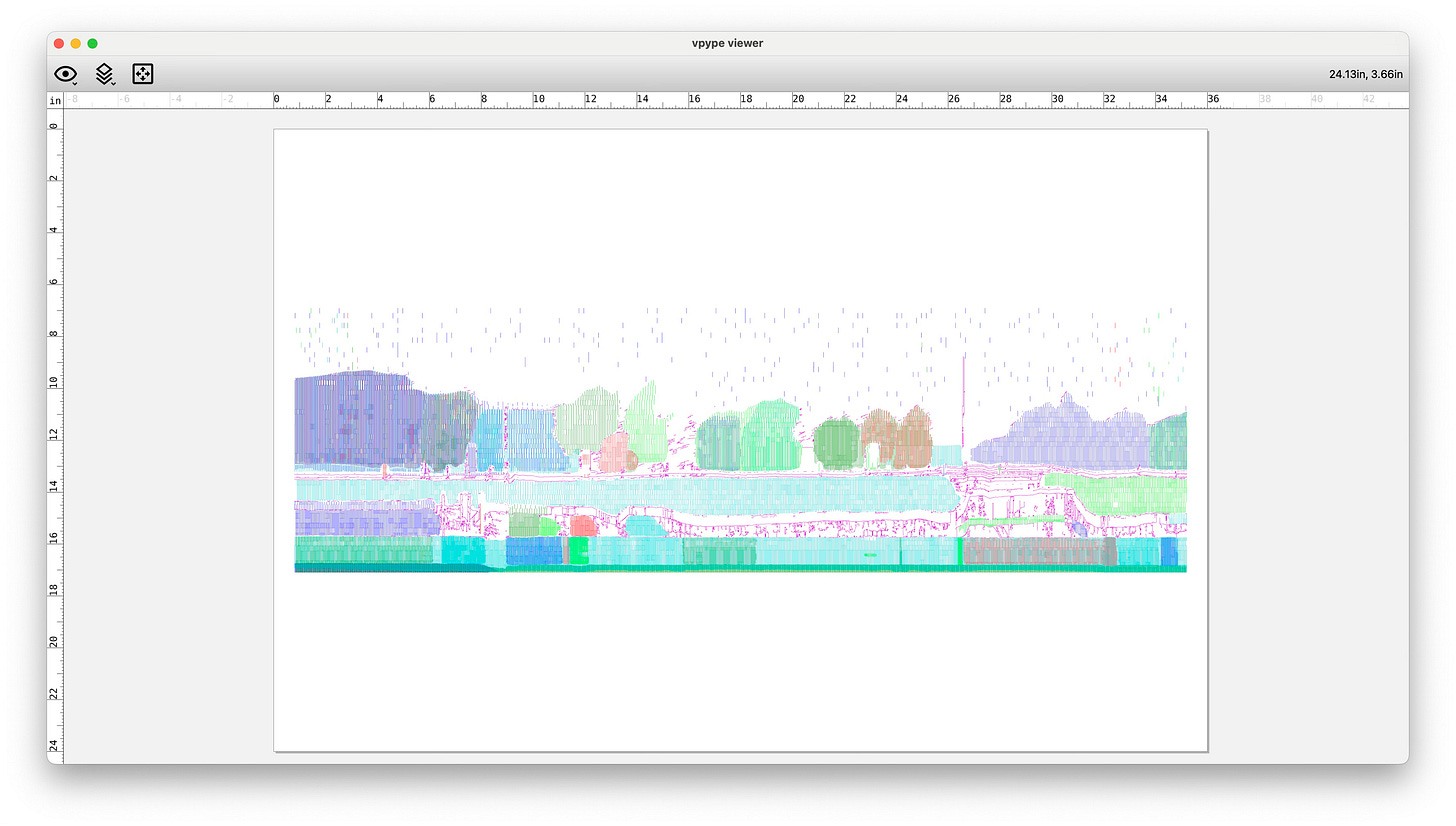







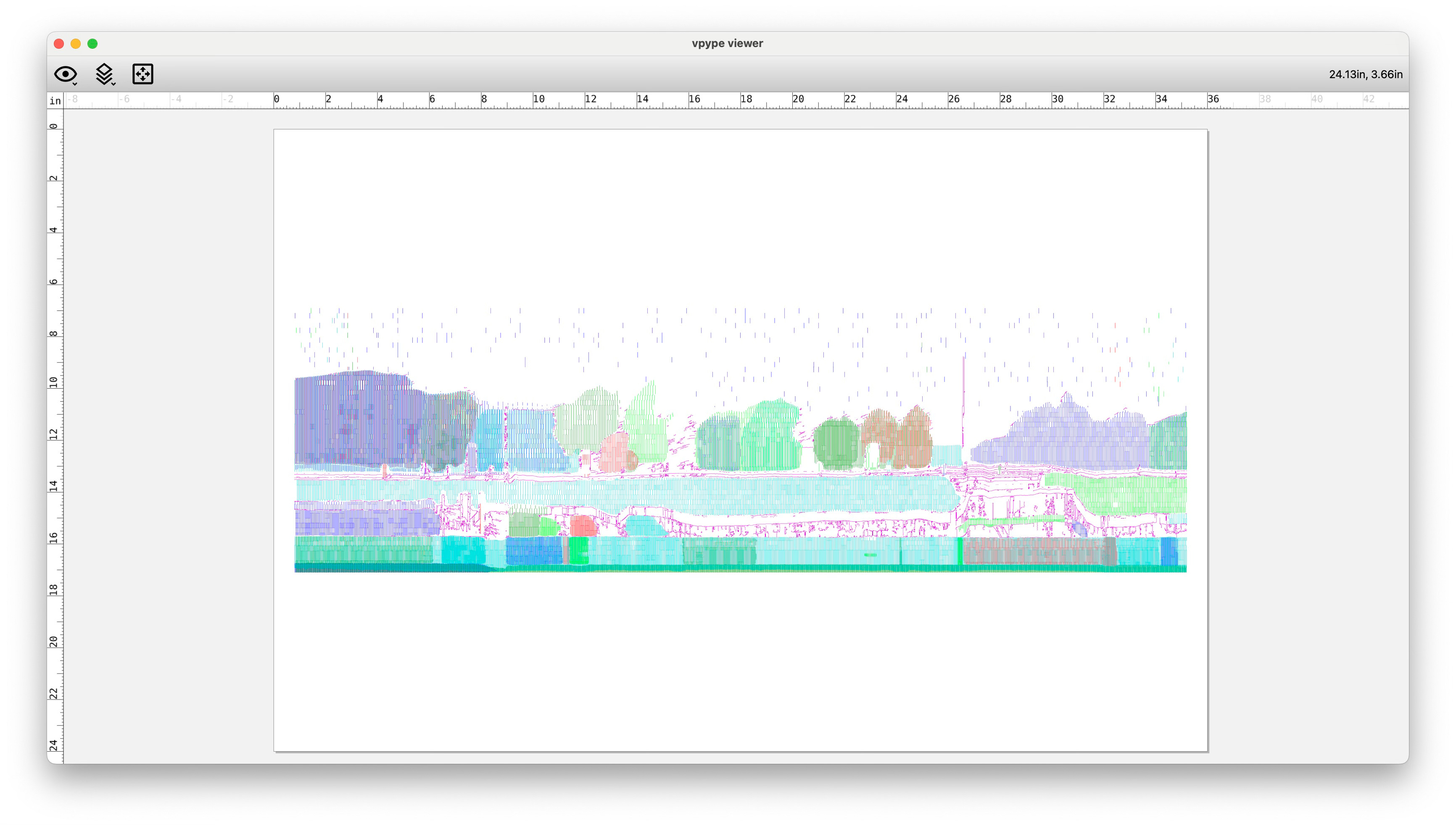
Some results!



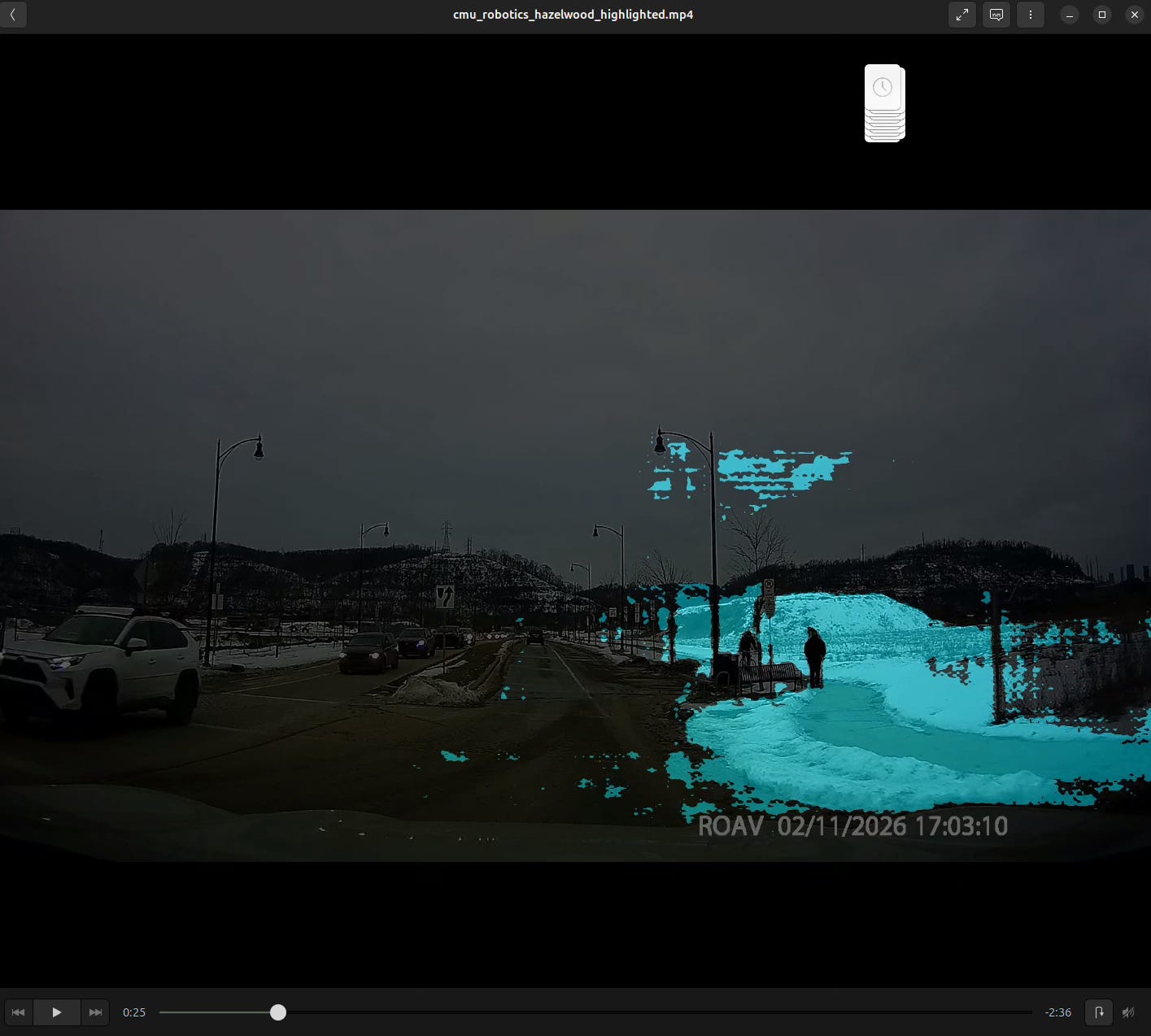
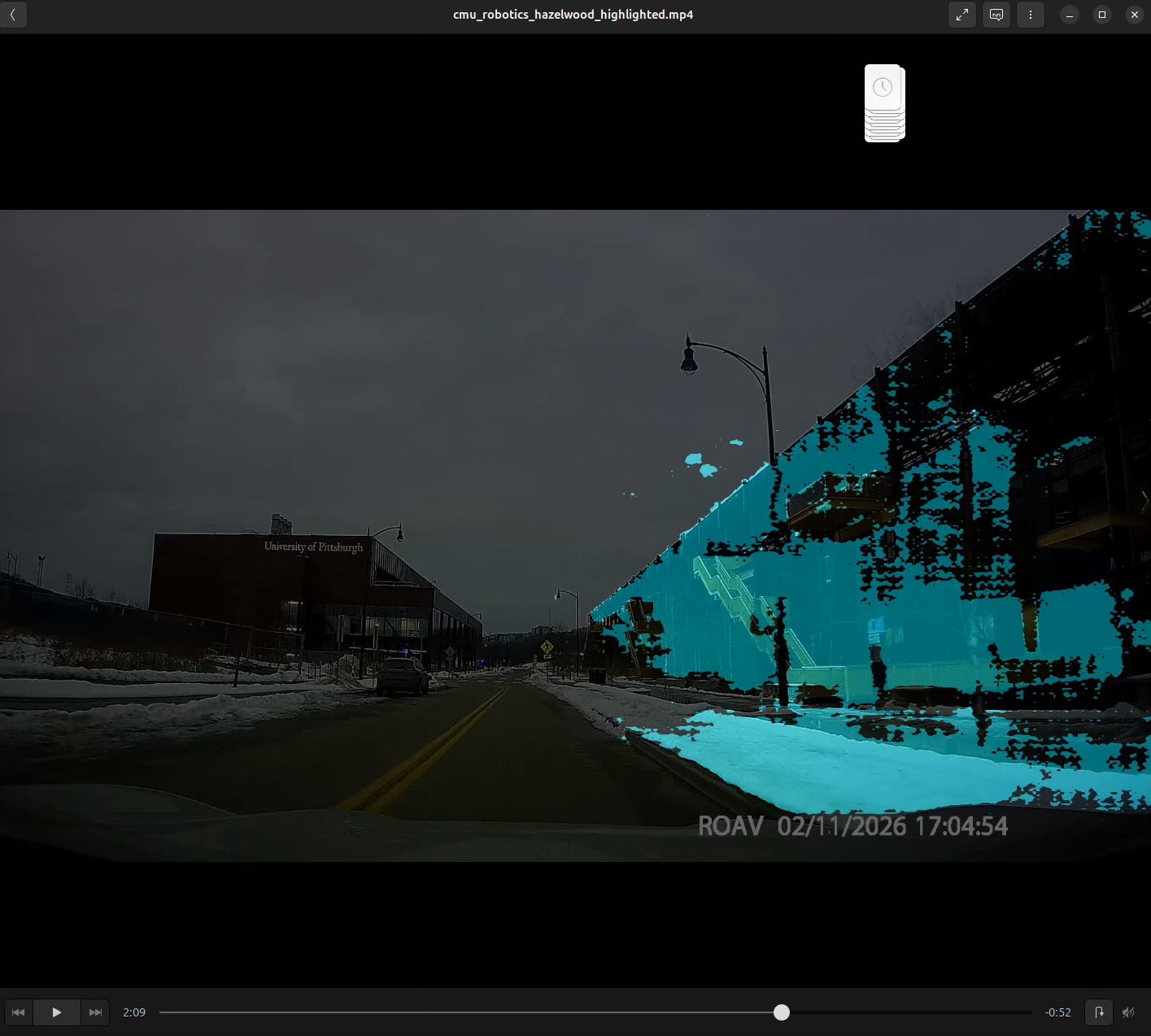
Another exploration I did with this dashcam footage was more semantic segmentation – this time directly on the video with hopes to extract just the snow from the snowstorm a month ago. A bit of a fail, need to do some more work on it.
Another brief exploration was to take advantage of the forward motion of a car moving forward and to generate a gaussian splat (it returns!) using Inria’s On the Fly Novel View Synthesis paper/code. Not bad, but I think the subject is lacking in this case.

But it does work so….
What’s next…
I think there are some key things that I like in each project:
Preserving a kind of experience of a medium.
Use of an analytical algorithm to reveal something different.
Subverting an existing medium(?).
Gaussian splats.
I think I might be able to obtain some footage of some buildings in LA via friends in places. With Professor Yannis, I’m working on developing a variation of 2DGS (which is 3DGS but instead of 3D blobs, you use 2D disks) that might create a better model of buildings with lots of planar surfaces with a lot less floaters (stray 3D blobs in a IRL empty space). The tricky part is how to show this to people. I don’t like the idea of AR/VR – that has a hardware hurdle for an audience that I’d like to avoid. Leaning on the idea of a web viewer but idk man.
I’ve been writing this for the past 6 hours and shall end it here. Cheers!