A week exploring the Getty Collection
Went to LA right after senior fall finals to photograph cameo gems! TLDR: didn't work because gems aren't opaque (shocker)

Overview-ish


In December, I spent a week after finals at the Getty Villa photographing cameo gems. Cameos are produced using the cameo technique: carving a relief (raised, positive) image into layered materials that contrast in color. They're relatively rare artifacts that typically depict portraits of royalty or scenes from Greek and Roman mythology — the kind of thing you find in museums or, in my case, a private collection belonging to a wealthy patron.
This project explores the application of a computational photography technique called confocal stereo to cameo gems, in pursuit of two questions:
Using hardware and software already present in cultural heritage institutions, can depth information be extracted from antiquities — and can that data be meaningfully applied to open-source initiatives, merchandising, and further analysis?
How effective is confocal stereo on cameo gems specifically?
Spoiler: the answer to the first question is yes. The answer to the second is... not really.
Confocal stereo is a method of computing 3D shape by precisely controlling the focus and aperture of a lens. If you're familiar with focus stacking, this is that — on steroids. For the uninitiated: focus stacking is a digital imaging technique that combines multiple images of a scene, each captured at a different focal depth, to produce one sharply focused composite. It's especially useful in macrophotography and landscape photography, where no single focus setting captures everything cleanly.
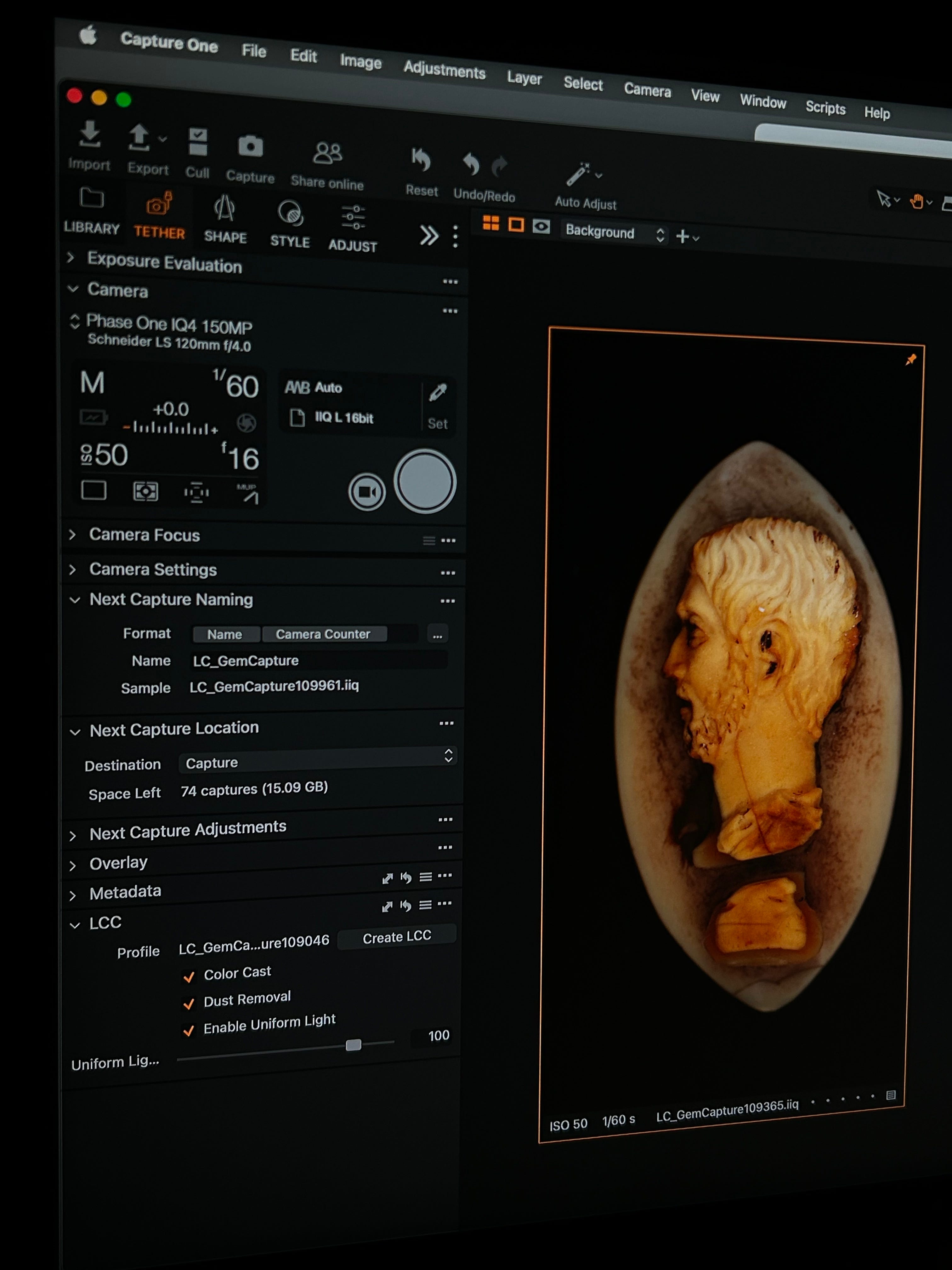
In cultural heritage, focus stacking is widely used to produce high-fidelity images of objects ranging from small gems to large sculptures. Niki Nakagawa, Senior Photographer at the Getty Villa Imaging Studio, told me that institutions like the Getty typically work with cameras and software purpose-built for focus stacking. Industry standards include Capture One software, Phase One cameras, and Hasselblad cameras.
Confocal stereo was chosen here specifically because it works within that existing hardware and software ecosystem — no new equipment required. The goal was to extract depth and 3D shape data from the gems using tools cultural heritage institutions already have. That said, the translucent nature of some gems (especially glass ones) introduced significant noise in the results, as you'll see below.
Setup
I worked with Niki using the Getty’s Capture One Pro software and a Phase One XF camera with a Phase IQ4 digital back. The lens was a Schneider 120mm macro, and lighting came from two broncolor Picobox units.
To reduce specular reflections, we applied cross-polarizers to both the lens and the lights:
Lens polarizer: B+W KSM HTC-POL MRC nano, XS-Pro Digital, 86mm
Light polarizers: American Polarizers, Inc. AP32-015T — Linear Polarizer, 32% Transmission, 0.015” thick

Confocal Stereo
Confocal stereo was first introduced by Samuel Hasinoff et. all in 2006.As described earlier, it reconstructs 3D shapes in scenes with high geometric complexity or fine-scale texture by controlling a lens's focus and aperture. In short, it uses the optics of the lens itself as the stereo system.
As focus and aperture vary, the way light enters the lens changes — altering the brightness and sharpness of each pixel. By analyzing how individual pixels change across a focus stack captured at multiple apertures, depth can be inferred. The foundational insight of the paper is something Hasinoff calls confocal constancy: as aperture varies, the intensity of a correctly focused pixel changes in a predictable, scene-independent way that can be established through prior radiometric lens calibration.
I first obtained calibration data by photographing a white planar surface across a range of apertures. From this, I constructed what Hasinoff calls an aperture-focus image (AFI). Unlike a standard image — defined by RGB values at position I(x, y) — an AFI records values at I(x, y, a, f), where a is aperture and f is focus setting.
From there, the algorithm searches for the focus value at which each pixel's intensity-to-aperture relationship matches what's expected for an in-focus point. When a scene point is perfectly focused onto a pixel, all rays from that point converge to the same location on the sensor, and the pixel's intensity scales proportionally with the aperture area. If a point is out of focus, rays from different parts of the aperture correspond to slightly different spatial locations, so the pixel collects a mixture of radiance from neighboring points — and that proportional relationship breaks down.
By evaluating this consistency across multiple focus settings, the algorithm identifies the focus value at which each pixel best satisfies the confocal constancy condition. That focus value maps directly to a depth estimate via the thin lens equation. Because each pixel is evaluated independently — with no need to find correspondences between multiple views — confocal stereo can recover fine structures that traditional stereo methods typically struggle with, like thin geometry or low-texture regions.
A caveat: confocal stereo assumes that the intensity at a pixel comes from a single, consistently radiating scene point. This holds reasonably well for diffuse (Lambertian) surfaces. It breaks down for specular or translucent materials. Specular surfaces reflect light in a strongly view-dependent way, so as the aperture changes, the pixel captures different radiance values that don't scale predictably — violating confocal constancy. Translucent materials scatter light internally, so the measured intensity may originate from a volume of points rather than one surface location. Both effects produce unreliable depth estimates, which explains much of the noise in the results below.
Results
The following image pairs show the original gem photograph alongside its corresponding depth output. A few notes on what you’re seeing and why the results look the way they do.
The outputs come in several forms. For ease of understanding, I have the raw image and the global focus index maps below. The global focus index maps (black and white) show the estimated depth at each pixel, encoded as the focus setting index at which confocal constancy was best satisfied.
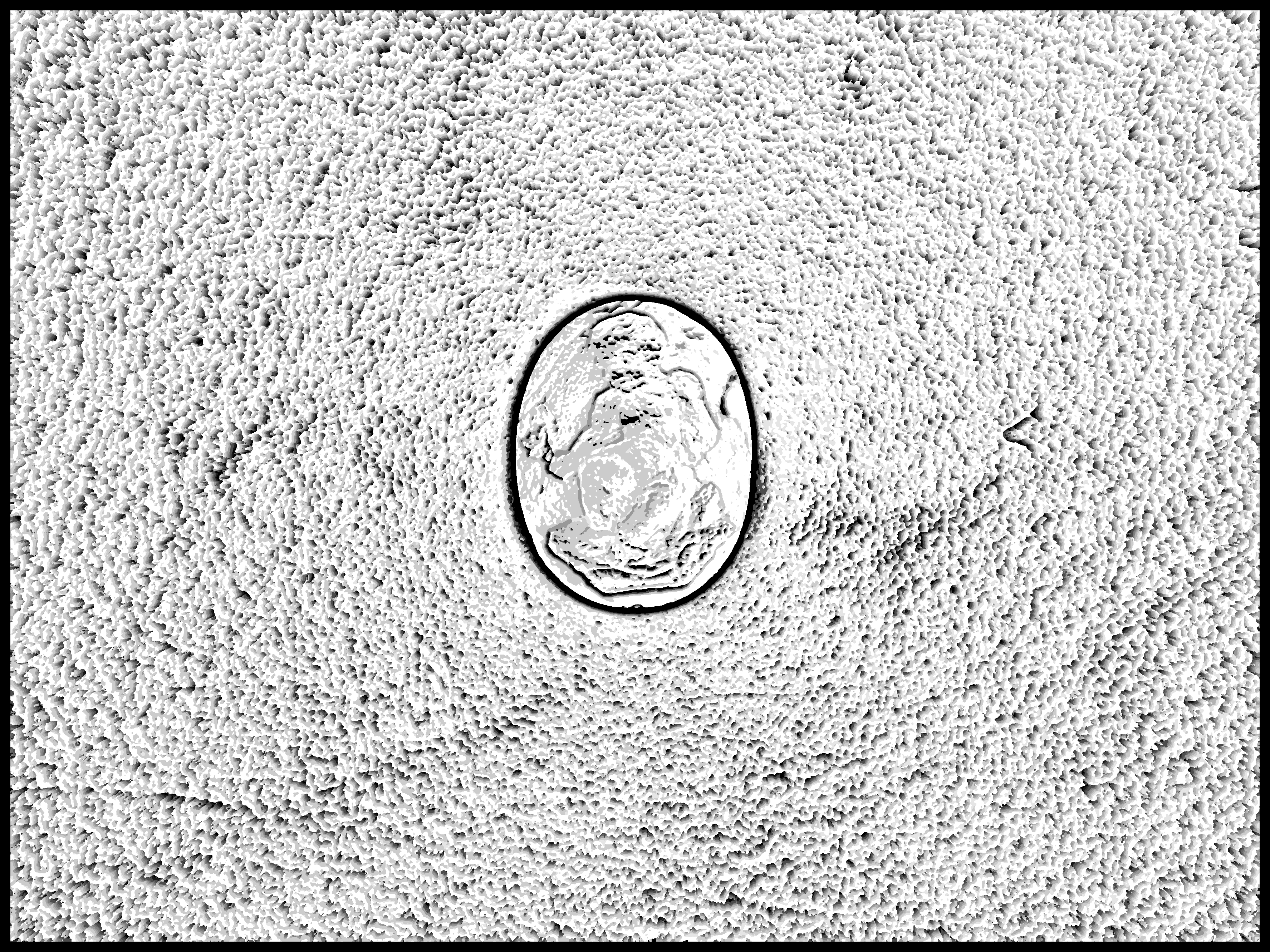

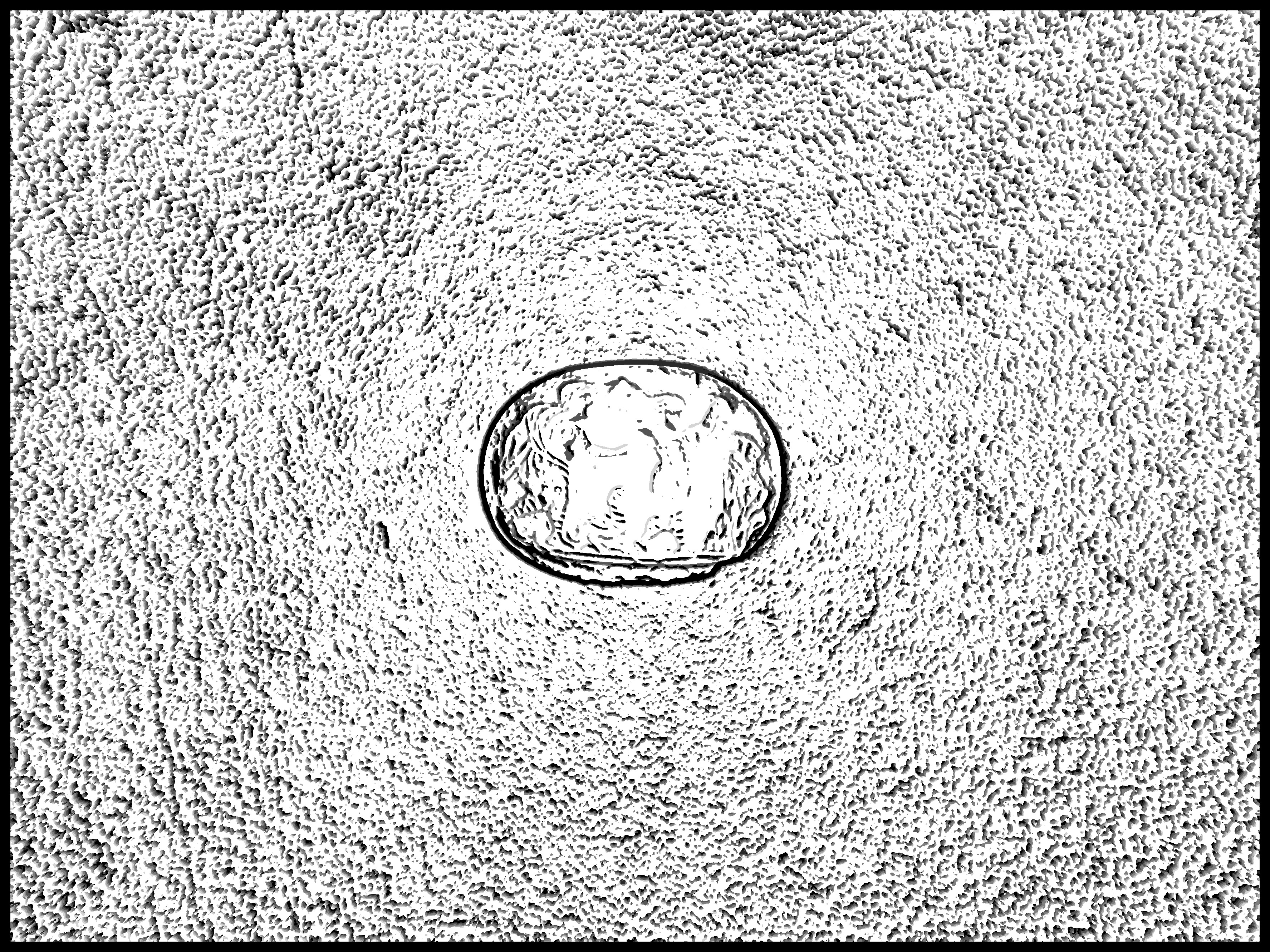
A few things worth pointing out across the results: the concentric ring pattern visible in the background of several outputs is a vignetting artifact from the lens, not scene geometry. The tile seams visible in some results are a consequence of processing the high-resolution images in patches with slightly uneven sizing. Most notably, the gem itself — the region of actual interest — tends to show the highest noise and lowest confidence. This is precisely what the theory predicts: the translucent and semi-specular material of the gems violates the diffuse surface assumption that confocal stereo depends on. The algorithm can’t reliably distinguish whether intensity variation across apertures reflects depth or the material’s optical properties.
That said, the gem boundary is often recoverable — the sharp edge between the gem and its backing provides a clean depth discontinuity the algorithm can latch onto — and the qualitative shape of the relief is faintly legible in several outputs, even if it’s too noisy for precise 3D reconstruction.
Reflections
Technical Notes
I'll be the first to admit I didn't take this as far as I'd like. One possible continuation: I did a brief earlier project making large 3D-printed relief sculptures of friends using meshes derived from Gaussian splats. It would be interesting to combine the depth data from this project with a state-of-the-art monocular depth model like DepthAnything to generate modern cameo-style sculptures of profile pictures from social media. That's a whole other undertaking I don't currently have bandwidth for — but we'll see.



I'd also love to revisit this technique on a diffuse-surface antiquity, like these relief-decorated altars in the Getty Collection. The material would better satisfy confocal stereo's assumptions, though it's worth noting the technique may not outperform DepthAnything significantly in those conditions. Another interesting subject: rugs or textiles, since confocal stereo handles fur, hair, feathers, and fibrous surfaces particularly well. That might warrant reaching out to the Costume Institute at the Met or a similar fashion-focused cultural heritage institution.
One last note: I'm about 95% confident in my implementation. Fortunately, Sam Hasinoff was kind enough to upload all 43.4 GB of data from the hair example on the project page — so if I find the time, I'll use that to verify correctness.
Personal Notes
This experience deepened my interest in applying analytical computational methods within culturally significant contexts.
I’ve taken courses that engage with generative AI, and what I’ve found is that working strictly with tools like MidJourney or similar image generation systems rarely surfaces something fundamentally new. Cultural heritage is different — it frequently brushes up against nuanced questions in media theory.
"The medium is the message" is an idea I first encountered in a Decision Science course called Thinking in Person vs. Thinking Online. In cultural heritage contexts, we're often dealing with stories that have been told through many different mediums across time. Documentation inevitably raises the question: what exactly should we be preserving when new technologies emerge?
The History of Information is a lovely source that I encountered while researching the history of cameo gems, and it describes the paradoxical loss of data that can occur during technological transitions:
Ironically, it has proved to be the moments of major change in physical form—which one might expect to have increased the texts’ chances of survival—that have seen the greatest volume of physical loss: the changes from roll to codex, from tribal scripts to Caroline minuscule, and from script to print; for once a body of literature is consigned to a new physical form, what remains in the old form, now redundant, is discarded” (R. Rouse,” The Transmission of the Texts,” Jenkyns [ed] The Legacy of Rome. A New Appraisal [1992] 42-43).
This raises a question I think deserves more serious attention: what are we choosing to capture with the convenient tools that technological innovation provides? Selection and curation — intentional or not — are embedded in how we record and understand the world. Computational tools offer the possibility of a different kind of record, one that preserves information future generations might find meaningful in ways we can’t yet anticipate. Every medium shapes its own definition of an object; a digital twin captures something different from what a time-based archive would.
In practical conservation contexts, this kind of documentation has already proven its value — detailed 3D scans of Notre Dame Cathedral, for instance, played a significant role in guiding reconstruction after the 2019 fire.
On the analytical side, part of my time at the Getty involved learning how the imaging department supports conservation science through scientific imaging, including spectral and 3D imaging techniques. One highlight was a demo of a reflectance imaging spectroscopy system. It records spectral reflectance across visible and short-wave infrared wavelengths. By measuring the spectral reflectance properties across different regions of an object, researchers can cluster and characterize the materials present. This is often useful for pigment identification and mapping, and aids in better understanding artists’ preferred materials and working methods



Credits because many hands make light work
I’m incredibly grateful for this opportunity, which wouldn’t have happened without Professor Golan Levin’s introduction and the broader community at the Getty Institute.
This project was supported by undergraduate grants at CMU, including the Studio for Creative Inquiry’s FRFF Micro Grant, the BXA Small Grant, the CFA Small Grant, and the School of Art Small Grant.
Special thanks to the Getty Villa’s Digital Imaging Team and other specialists I met:
Niki Nakagawa - Senior Photographer, Villa Imaging Studios
Tahnee Cracchiola - Imaging Manager, Villa Imaging Studios
Dr. Olivia Kuzio - Lead Technical Imaging Specialist (Hyperspectral Camera demonstration)
Thomas Boers - GCI Science Department 2025-2026 Graduate Intern (Hyperspectral Camera demonstration)
Tom Keep - Center Imaging Studios 2025-2026 Graduate Intern (brief discussion of Confocal Stereo techniques and Photogrammetry Rig)
David Newbury - Senior Director of Public Technologies
Todd Swanson - Digital Imaging Director
Enormous thanks to Professor Golan Levin (CMU) for the guidance and the introduction that made this possible.
Many thanks to Professor Ioannis (Yannis) Gkioulekas (CMU) for his technical guidance on all things computational imaging, vision, and graphics.
(Self-appreciation warning:) Grateful to 18-year-old me for choosing CMU BCSA over BRDD.
A paper version of this project was submitted for Professor Yannis’s Computational Photography course in Fall 2025 — not included here. The course was an invaluable introduction to computer vision and graphics techniques that I genuinely needed.
And finally: shoutout to the motorcyclist who rear-ended me on the way to the airport. Thanks for the slight trauma and for making this experience even more unforgettable.
Thank you for reading this documentation that took me way too long to write.
Peace and love, Lorie :3
Extras!
Some pics that didn’t fit in the narrative above with no context.



